Profiling augr's performance
I built a time tracking software named augr, and recently decided that it
was time to make it faster. For some context, these were the results of running
time augr:
~/p/u/augr ((8776075c…)|…) 1 $ time ./target/release/augr summary
# snip
0.22user 0.01system 0:00.23elapsed 99%CPU (0avgtext+0avgdata 7204maxresident)k
0inputs+0outputs (0major+948minor)pagefaults 0swaps
This is before I did any optimization.
Shock! Horror! Running one command takes a whole fifth of a second? How could anyone work under these conditions!
Ahem.
So, augr didn't really need to be faster. I wanted to make it faster,
because I use augr several times a day, often on my phone. I also wanted to
gain some experience optimizing, as I don't have much experience doing that.
And so, my journey began.
(Just a note, I didn't actually save most of the performance reports, so the graphs shown here are not the exact graphs I saw.)
Act 1: Thought Processes
The first thing I needed to do was find the right tool for the job. augr is
written in rust, so I looked for stuff along the lines of "rust profiling
code".
After reading this article, I decided to use cargo-profiler.
~/p/u/augr ((8776075c…)|…) 1 $ cargo profiler callgrind --bin target/release/augr -n 10 -- summary
Profiling augr with callgrind...
Total Instructions...909,402,627
245,396,401 (27.0%) ???:_int_malloc
-----------------------------------------------------------------------
118,210,891 (13.0%) ???:_int_free
-----------------------------------------------------------------------
64,236,762 (7.1%) ???:__memcpy_avx_unaligned_erms
-----------------------------------------------------------------------
64,135,017 (7.1%) ???:malloc
-----------------------------------------------------------------------
41,613,000 (4.6%) ???:<toml::tokens
-----------------------------------------------------------------------
37,643,653 (4.1%) ???:malloc_consolidate
-----------------------------------------------------------------------
31,174,650 (3.4%) ???:<alloc::collections::btree::map
-----------------------------------------------------------------------
29,340,320 (3.2%) ???:free
-----------------------------------------------------------------------
25,118,543 (2.8%) ???:<alloc::collections::btree::map
-----------------------------------------------------------------------
24,456,263 (2.7%) ???:<alloc::collections::btree::map
-----------------------------------------------------------------------
Immediately, this tells us that most of the program runtime is being spent on
allocation. It also tells us that the allocation is most likely being done in
a BTreeMap.
Hmm.
At this point I decided that I needed something to tell me more specifically where my code was slow. I kept looking for tools.
Linux perf
The next thing I tried was the Linux perf profiler. It's a very shiny
looking tool for measuring the performance of a program. It even had a nice
interactive report tool:
Samples: 36 of event 'cycles:ppp', Event count (approx.): 877654027
Overhead Command Shared Object Symbol
36.58% augr [kernel.kallsyms] [k] __d_lookup_rcu
9.92% augr libc-2.27.so [.] _int_free
7.95% augr libc-2.27.so [.] __memmove_avx_unaligned_erms
5.96% augr augr [.] <augr_core::repository::event::PatchedEvent as core::clone::Clone>::clone
5.95% augr libc-2.27.so [.] _int_malloc
3.97% augr augr [.] <alloc::collections::btree::map::IntoIter<K,V> as core::ops::drop::Drop>::drop
3.08% augr [kernel.kallsyms] [k] copy_page
2.46% augr augr [.] __rust_alloc
2.19% augr augr [.] <alloc::collections::btree::map::BTreeMap<K,V> as core::clone::Clone>::clone::clone_subtree
2.08% augr augr [.] <alloc::collections::btree::map::BTreeMap<K,V> as core::ops::drop::Drop>::drop
2.03% augr augr [.] <alloc::collections::btree::map::BTreeMap<K,V> as core::clone::Clone>::clone::clone_subtree
1.99% augr augr [.] <alloc::collections::btree::map::BTreeMap<K,V> as core::clone::Clone>::clone::clone_subtree
1.98% augr augr [.] toml::tokens::Tokenizer::next
1.98% augr augr [.] <toml::tokens::CrlfFold as core::iter::traits::iterator::Iterator>::next
1.98% augr libc-2.27.so [.] cfree@GLIBC_2.2.5
1.98% augr libc-2.27.so [.] malloc
1.98% augr libc-2.27.so [.] malloc_consolidate
1.98% augr augr [.] __rust_dealloc
1.98% augr augr [.] <alloc::collections::btree::map::BTreeMap<K,V> as core::ops::drop::Drop>::drop
1.98% augr augr [.] toml::ser::Serializer::emit_str
0.01% .perf-w [kernel.kallsyms] [k] native_write_msr
Press '?' for help on key bindings
In the end, I decided that it wasn't the tool I needed. The report gave me about
the same information as cargo-profiler. It seems like a very powerful tool,
but I didn't want to take the time to learn it.
Flamer
The flame and flamer crates allow you to generate flame graphs
by annotating your code or calling flame::start() and flame::end().
They're essentially fancy crates for println debugging.
Because flame and flamer require you to mark up your code, and I wanted to
save the changes I made, I made a flame_it feature as recommended in
flamer's README.
Anyway, this is the flame graph before I made any changes:
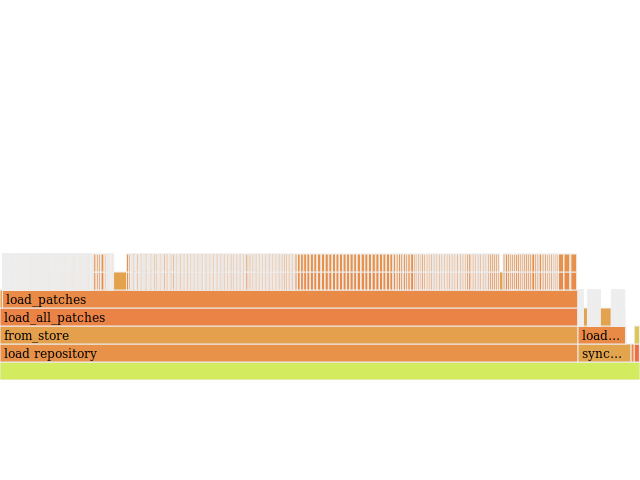
"Aha!" I said at this point. "augr appears to be slowing simply because of
the number of files that need to be loaded! There are lots of clever ways to
make this faster. I could make a cache file, or I could do some kind of
automatic merging of files, or..."
It was at this point that I decided to take a moment and actually investigate the problem before rushing into a giant project to fix it. I added a some code to track how long loading the files took.

The little orange rectangle at the top left of the stack is how long it took to load that patch from disk. So it wasn't the number of files.
After a bit more investigating that is harder to screenshot, I determined that applying the patches was taking a majority of the time, not loading them.
Making Things Faster
So what made this code slow?
pub fn apply_patch(&mut self, patch: &Patch) -> Result<(), Vec<Error>> { // Clone state let mut new_state = self.clone(); // Make changes to state // *snip* // Save changes to state if there were no errors if errors.len() >= 1 { Err(errors) } else { self.events = new_state.events; Ok(()) } }
Oh. As it turns out, cloning your entire state for every operation is bad for performance. In addtion to that gem, there were about 20 other calls to clone in that block of code.
At this point, the I realized that the performance reports from
cargo-profiler confirmed that the cloning was killing performance, especially
with the other point of information about BTreeMap cloning, as the state was
just a big BTreeMap.
The problem was that I couldn't make changes before I knew that the patch was valid. After a bit of thinking, I realized that patches could be verified before mutating the state. The code would ensure a patch is valid, and then just mutate the state directly, as it's already "checked the bounds", so to speak.
After making the required changes, augr ran much faster:
~/p/u/a/cli ((d4536c4e…)|…) 1 $ time ../target/release/augr
# snip
0.07user 0.00system 0:00.08elapsed 100%CPU (0avgtext+0avgdata 6192maxresident)k
0inputs+0outputs (0major+714minor)pagefaults 0swaps
But We Gotta Go Faster
Let's take a look at the flamegraph, now that we've made augr faster:
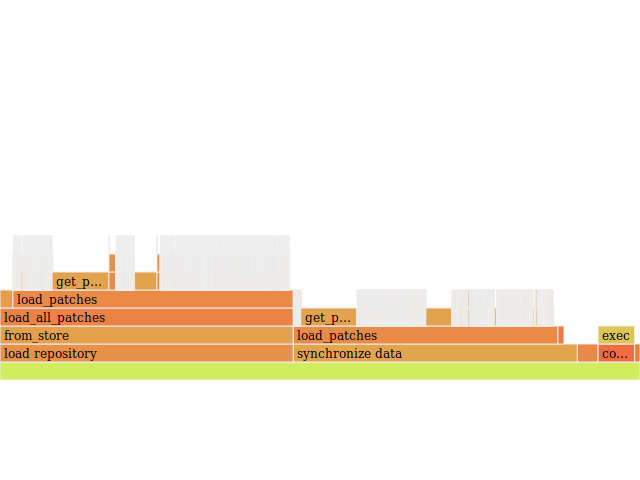
Hmm. Two calls to load_patches, that look identical? It turned out that the
patches were being loaded twice. I had code checking if a patch had already
been applied, but that was only checked after the patch had been loaded a
second time. Fixing that gave augr another boost in performance:
~/p/u/augr ((3ec64318…)|…) 1 $ time ./target/release/augr
# snip
0.02user 0.00system 0:00.03elapsed 100%CPU (0avgtext+0avgdata 6364maxresident)k
0inputs+48outputs (0major+707minor)pagefaults 0swaps
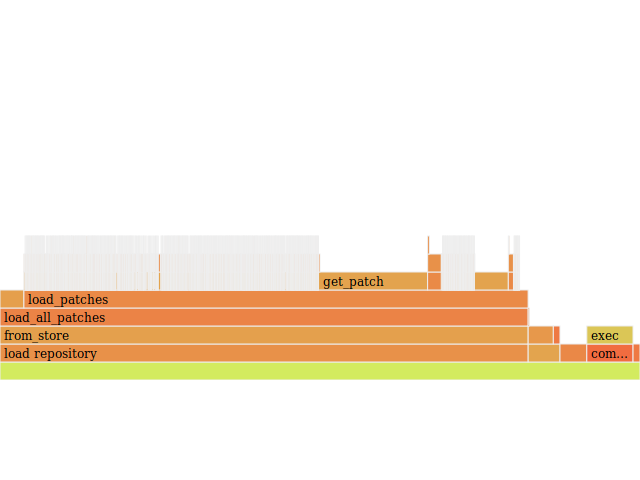
At this point augr was ten times faster than when I began, clocking in at 0.02s.
Conclusion
Measuring performance was kind of fun! In this case, I just had to make two simple changes and got a 10x improvement.
Measuring was also more effective than my wild guessing. In my head, I assumed
that loading so many files was going to be the bottleneck, and I thought I was
going to need all kinds of crazy caching systems to make augr faster. But I
didn't need anything remotely like that!
Always measure before optimizing, kids.
(P.S. After optimizing augr, I learned about a replacement for time called
hyperfine! It's much nicer, and I recommend it.)
(P.P.S. I also learned about flamegraph. Go check it out! It allows you
to skip the whole "annotate your code" thing and profile arbitrary binaries. It
also has a lot of good advice in its README. Check it out!)